MLCD-Embodied 🤖
MLCD-Embodied is comparable to 4v in terms of embodied capabilities and possesses excellent general capabilities. The detailed evaluation results are shown below.
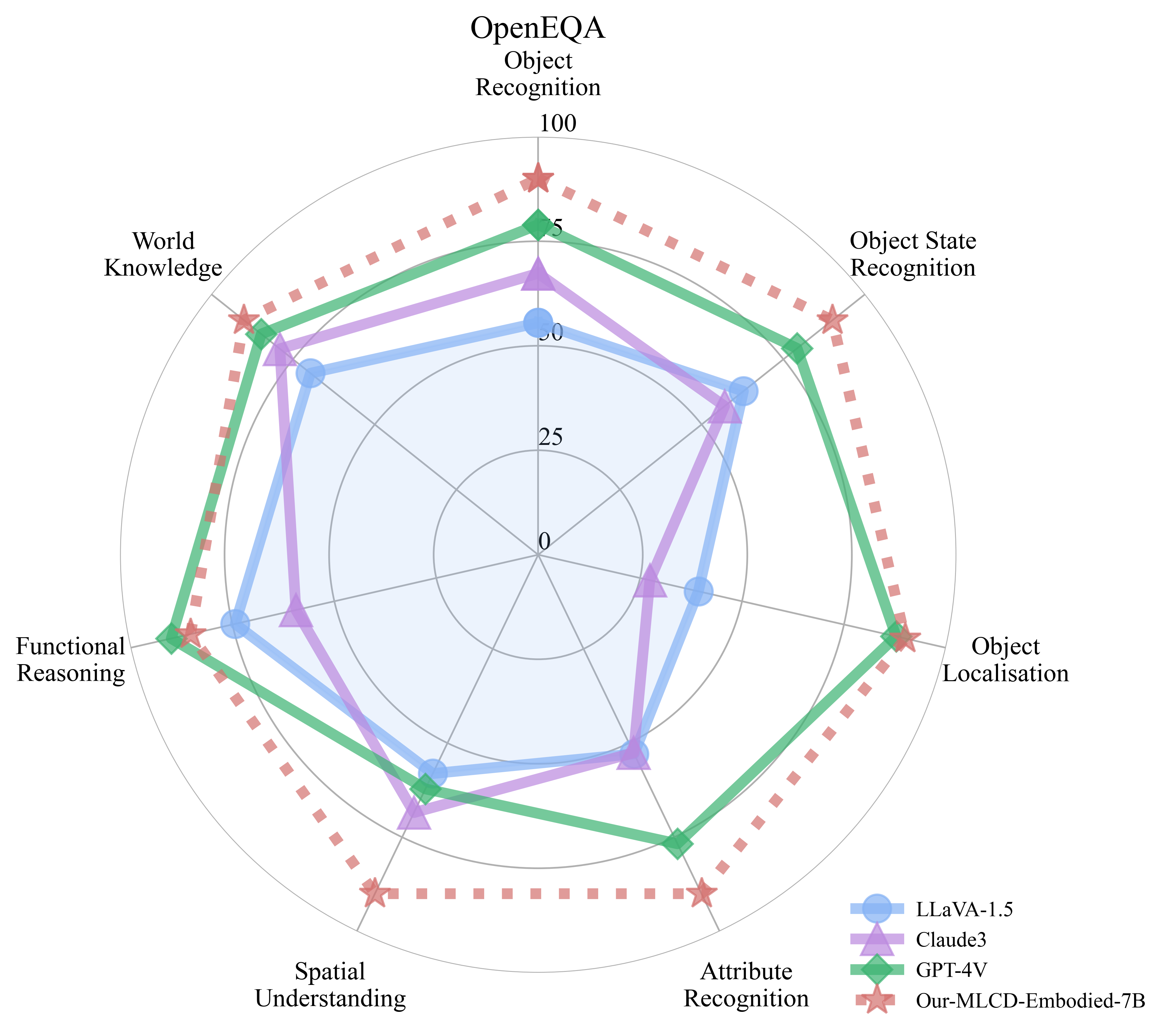
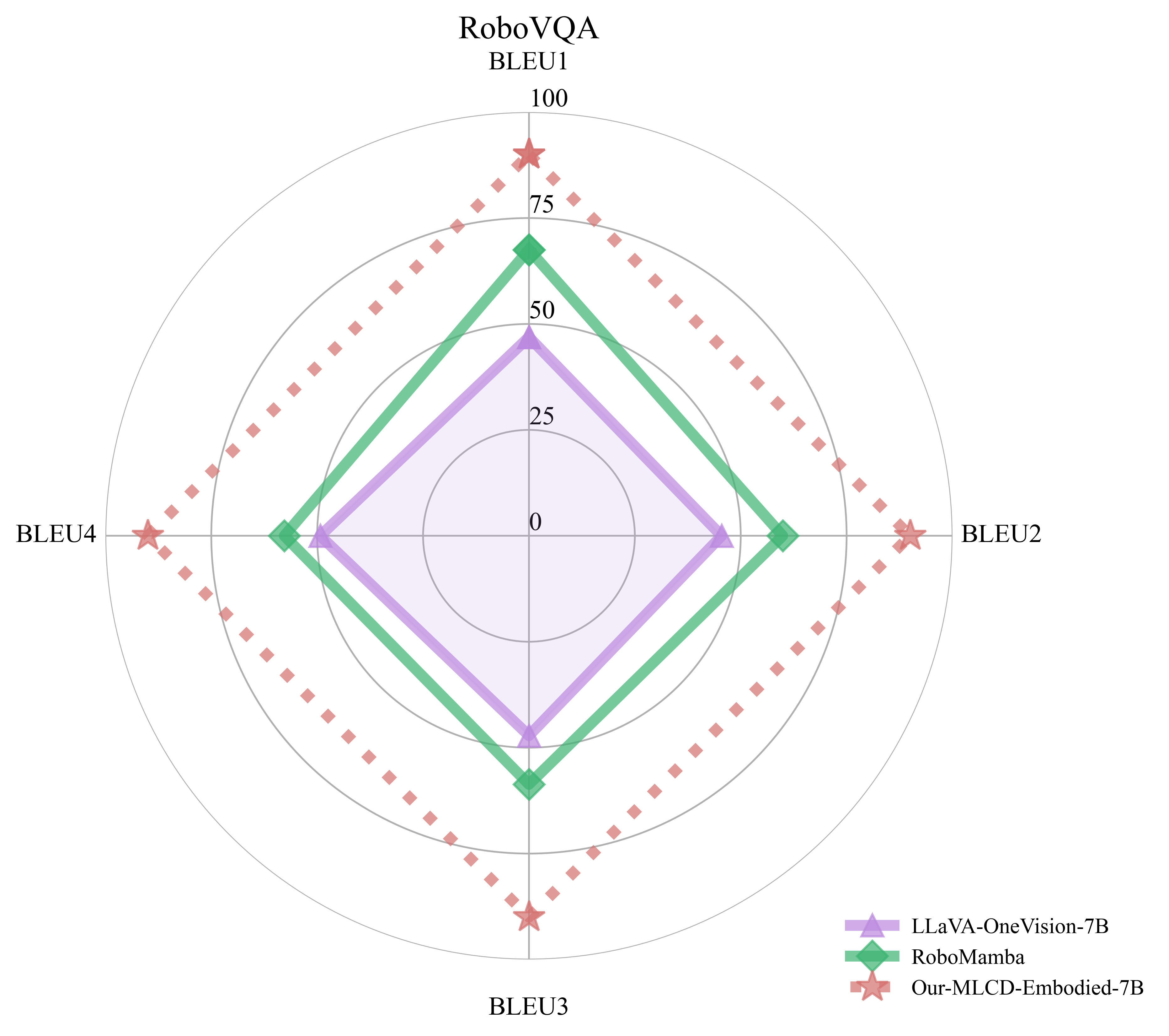
Embodied Ability Evaluation: Performance in RoboVQA and OpenEQA
MLCD-Embodied-7B |
LLaVA OneVision-7B |
GPT-4V |
RoboMamba |
||
|---|---|---|---|---|---|
RoboVQA |
BLEU1 |
73.16 |
38.12 |
- |
54.9 |
BLEU2 |
66.39 |
33.56 |
- |
44.2 |
|
BLEU3 |
60.61 |
31.76 |
- |
39.5 |
|
BLEU4 |
56.56 |
30.97 |
- |
36.3 |
|
OpenEQA |
OBJECT-STATE-RECOGNITION |
71.83 |
- |
63.2 |
- |
OBJECT-RECOGNITION |
49.46 |
- |
43.4 |
- |
|
FUNCTIONAL-REASONING |
54.38 |
- |
57.4 |
- |
|
SPATIAL-UNDERSTANDING |
48.64 |
- |
33.6 |
- |
|
ATTRIBUTE-RECOGNITION |
67.08 |
- |
57.2 |
- |
|
WORLD-KNOWLEDGE |
53.87 |
- |
50.7 |
- |
|
OBJECT-LOCALIZATION |
43.06 |
- |
42.0 |
- |
General Ability Evaluation: Comparison with LLaVA OneVision-7B and GPT-4
Dataset |
Split |
MLCD-Embodied-7B |
LLaVA OneVision-7B |
GPT-4v |
GPT-4o |
|---|---|---|---|---|---|
A12D |
test |
79.9 |
81.4 |
78.2 |
94.2 |
ChartQA |
test |
83.0 |
80.0 |
78.5 |
85.7 |
DocVQA |
test |
91.6 |
87.5 |
88.4 |
92.8 |
InfoVQA |
val |
73.9 |
70.7 |
- |
- |
InfoVQA |
test |
70.0 |
68.8 |
- |
- |
MMMU |
val |
47.3 |
48.8 |
56.8 |
69.1 |
MMStar |
test |
58.5 |
61.7 |
57.1 |
63.9 |
OCRBench |
- |
749.0 |
697.0 |
656.0 |
805.0 |
RealWorldQA |
test |
68.9 |
66.3 |
61.4 |
58.6 |
SeedBench |
image |
74.9 |
75.4 |
49.9 |
76.2 |
MMbench |
en-dev |
81.1 |
83.2 |
81.3 |
83.4 |
MMbench |
en-test |
80.1 |
80.8 |
75.0 |
- |
MME |
test |
578/1603 |
418/1580 |
517/1409 |
- |
Usage
A. Installation
git clone https://github.com/deepglint/unicom
cd unicom
# Upgrade pip and install necessary dependencies
pip install --upgrade pip
pip install -e ".[train]"
B. Inference
CUDA_VISIBLE_DEVICES=0 python infer.py --model_dir /path/to/your/model
# example:
# >> Enter 'exit' to end the conversation, 'reset' to clear the chat history.
# >> Enter image file paths (comma-separated): ./asserts/logo.png
# >> User: <image>What kind of animal is it in this picture?
# >> Assistant: The image features a stylized representation of a cat, characterized by its vibrant and abstract depiction.
# >> User: What color is this cat?
# >> Assistant: The cat in the image is primarily white with blue, orange and pink accents, creating a visually appealing and unique appearance.
C. Evaluation for Embodied Ability
Step 1
Step 2
Converting raw data into the format required for model evaluation.
# convert OpenEQA benchmark. Note: replace the paths with your own.
python llava/benchmark/make_openeqa_bmk.py
# convert RoboVQA benchmark. Note: replace the paths with your own.
python llava/benchmark/make_robovqa_bmk.py
Step 3
Make sure that your top-level directory structure should look like this:
|--/path/to/your/benchmarks
| |--OpenEQA
| | |--openeqa_scannet.parquet
| | |--openeqa_hm3d.parquet
| |--RoboVQA
| |--robovqa.parquet
|--/path/to/your/images
|--openeqa_val
| |--scannet-v0
| | |--002-scannet-scene0709_00
| | |--xxx-scannet-scenexxxx_xx
| |--hm3d-v0
| |--000-hm3d-BFRyYbPCCPE
| |--xxx-hm3d-xxxxxxxxxxx
|--robovqa_val
|--robovqa_221911
|--robovqa_xxxxxx
Step 4
Run script for evaluation
# Note: replace 'YOUR_API_KEY', 'YOUR_ENDPOINT', 'bmk_root', 'image_folder' with your own.
bash scripts/eval/eval_robo.sh /path/to/your/model
D. Evaluation for General Ability
Install the evaluation tool and execute the evaluation script:
pip install lmms-eval==0.2.0
PYTHONPATH=./ CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m accelerate.commands.launch \
--main_process_port=12444 \
--num_processes=8 \
-m lmms_eval \
--model llava \
--model_args pretrained=DeepGlint-AI/MLCD-Embodied-7B,conv_template=qwen_1_5 \
--tasks mme \
--batch_size 1 \
--log_samples \
--log_samples_suffix mlcd \
--output_path ./eval_log/